Turn signals on cars have a dangerous flaw. This blog post explores that flaw, proposes a solution, and digs into what we can learn from it to build better software.
Traffic lights
Before we look at turn signals, we first need to discuss traffic lights as an example of a system that got it right.
Traffic lights operate in the following states:
Red: Stop
Green: Go
Yellow: Stop if possible because the light is about to turn red

Note that I said operate and not exist. There is one very important extra state in which these lights can exist: off.
When does the light exist in this state? When something has gone wrong.
The great thing about traffic lights is that you know exactly what to do, even in this state: watch out, use good judgement. There is no ambiguity about what any of the states mean, because they are all separate.
Indeed, you could imagine a design in which a traffic light would have only two lights: red, and green. In such a design, you might use "off" instead of yellow. However, the big problem with such a design is that you can no longer distinguish "Error" from "Yellow".
There are of course other error states. Some of which you cannot notice: "Green at the wrong time", for example. But you can notice most incorrect states: All lights on at the same time, or the top light being green, for example. Because of the extra redundancy in the valid states, you can easily notice such invalid states. (Note that even if colourblind people didn't exist, this would still be a good reason to have three separate lights instead of one light in three colours.)
In conclusion: traffic lights make it easy to notice defects by using redundancy to distinguish invalid states from valid states.
Turn signals
Now let's look at how turn signals work. There are three possible states:
Left turn signal on: Driver indicates they want to turn left.
Right turn signal on: Driver indicates they want to turn right.
Both turn signals off: Driver indicates they will continue straight.
Which state occurs when something goes wrong? One of the valid states.
When the driver forgets to indicate (a very common issue), both turn signals will be off, and it will look like they want to continue straight.
(Clearly the driver could also make a mistake by indicating left when they want to turn right, but this is not fixable.)
This is a fundamental problem with the turn signal system: The error state is the same as a valid state.
Indeed, other drivers can never tell the difference between "This driver will continue straight" and "This driver has forgotten to use their turn signals". This leads to much frustration but more importantly: real accidents.
Sure, it's easy to say that it was the forgetful driver's fault when an accident happens, but we would certainly prefer no accident to happen instead.
Fixing turn signals
To fix the issue of turn signals, we must add redundancy. We must find a way to distinguish between "forgetful driver" and "continue straight".
One way to do this would be to add a third "turn" signal at the front of the car between the headlights. Drivers would then have to use their front "turn" signal to indicate that they intend to continue straight.
Now other drivers can see the difference clearly:
All signals off: Driver is forgetful, watch out.
Front signal on: Driver intends to drive straight.
This system also has the nice property that it is backward compatible. If a car has "only" two turn signals, and a driver interprets them both being off as "watch out", that is not dangerous.
What we can learn from this to write software
In order to build robust systems, it is necessary to consider how the system might fail. Further more, the system should ideally be robust against failures that we had no idea could happen.
To do so, we can use this rule:
Make invalid states distinct from all valid states.
Here are some more examples in software:
When fetching data on the client-side of a web site, ensure that the user can see the difference between "The fetch yielded no data" and "The fetch is still in progress".
When fetching data, ensure that the user can see the difference between "The fetch is still in progress" and "The fetch has failed."
When tracking calories, ensure that you differentiate between "The user ate nothing" and "The user did not track anything yet."
We can go even further: If we know that we must distinguish between "missing data" and "no data", then we can make that easier by producing a system that works correctly with incomplete data. In other words:
Avoid assuming completeness.
Here are some examples of avoiding assuming completeness:
When using an address book, you never know if the data within it is still up-to-date. Someone's address might have changed between the time it was saved and the time it was read. If instead of only the address, we also save the time at which the address was last updated. This way we can tell the difference between "old, probably stale", and "new, probably not stale" by looking at the timestamp of the same address. In other words: If you assume that no one lies to the address book (soundness) then you can turn a situation where the address book is of unknown correctness into a situation where the address book data is definitely correct. This is done by changing the "facts" that the address book stores from facts of the form "person X has address Y" to facts of the form "person X had address Y on day Z".
When building a calorie tracker, we can add a button that lets users indicate that they have completed the tracking for the day. This way we can choose to only do computations with completed days. Here we've changed the facts from "A user has eaten any number of things, some of which include X, on day Y" to "A user has eaten exactly X on day Y".
When building a request monitoring system, don't consider "no requests came in" as "the same number of requests came in, but all of them failed". Sentry does this wrong, for example:
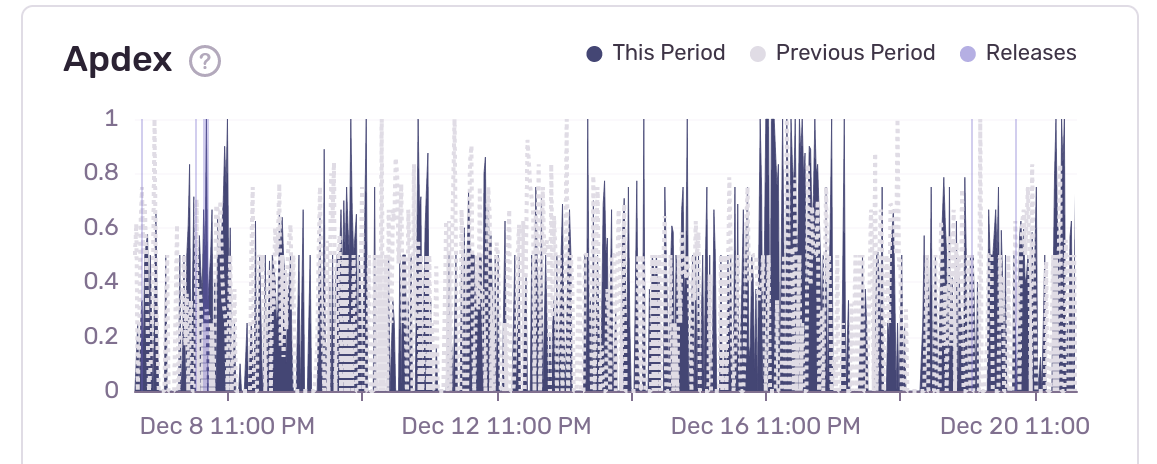
It computes the apdex as "ratio of satisfactory requests to total requests", but interprets "0 total requests" as "the worst possible apdex" (0). My site just does not have enough traffic for this metric to be useful if calculated in this way.
Conclusion
We can build more robust systems by following these two rules:
Make invalid states distinct from all valid states.
Avoid assuming completeness.