After building a web scraper for a university project, I decided I would build my own little web scraper for the single purpose of finding as many email addresses as possible. Eventually I could then send a message to each one of them, explaining that their email address was publicly visible a given url and how they should probably obfuscate it. I didn't quite get to the second part but I certainly found a whole bunch of email addresses.
The crawler pipeline
As it turns out, a crawler resembles a pipeline quite well. This immediately made me consider the pipes library.

Because there are loops in the pipeline, using vanilla pipes would not suffice. Luckily pipes-concurrency was well-equipped for this use-case.
pipes-concurrency makes use of thread-safe buffers to share data between pipelines. This allows for the architecture with loops as well as multiple concurrent fetchers.
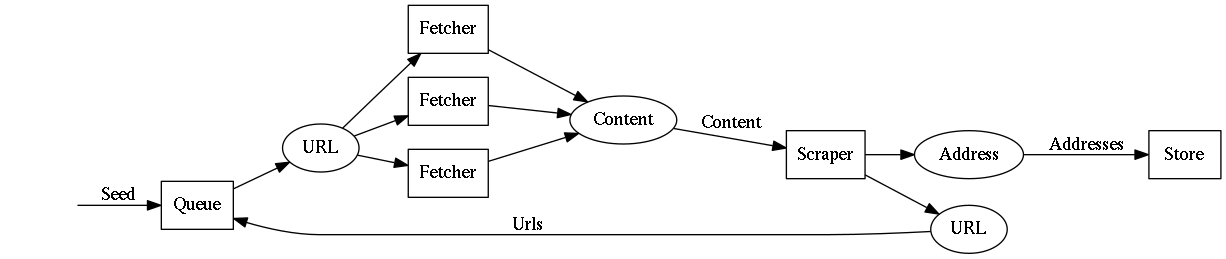
This looks like a nice architecture in theory, but how well does it translate to actual code? Think about it, how would you implement this in an imperative, object oriented language?
In Haskell, the pipes library takes care of the hard work. Once you've written the pipes, you can just stitch them together with >-> and have the library do all the work.
Inside a fetcher
Running multiple fetchers is little more than this line:
forM_ [1..n] -> i -> async $ runEffect $ fromInput uriIn >-> fetcher i >-> toOutput contentOutThe only thing a fetcher needs to take care of is transforming a URL into a (URL, Content) pair, possibly using IO.
Internally, the fetcher is made out of a bunch more pipes. Each of them taking care of a small part of the pipeline. Because finding email-addresses is all about recall and not as much about precision, we can just discard anything that presents a problem.
fetcher = prefetcher >-> contentFetcher
prefetcher = requestBuilder >-> prefetchRequester >-> statusCodeFilter >-> headerFilter >-> fstPicker
contentFetcher = requestBuilder >-> fetchRequester >-> statusCodeFilter >-> headerFilter >-> contentExtractorrequestBuildertakes a URL and produces a (URL, Request) pair and passes it on.prefetchRequesterandfetchRequesterboth fetch the page, the former using a HEAD request and the latter using a GET request. They take a (URL, Request) pair, produce a (URL, Response) pair and pass it on.statusCodeFilterthrows away any (URL, Response) where the the status code wasn't200, OK.headerFilterthrows away any (URL, Response) where the content type isn't text. This ensures that we don't look through binary data for email addresses.contentExtractorjust takes a (URL, Response) pair and emits a (Url, Content) pair.
As you can imagine, this makes for very easily composable code.
Memory footprint
A crawler has an inherent memory problem. Because there is generally more than one link on a web-page, keeping track of all found links in a queue will make for an exponential memory footprint with respect to runtime. This cannot be solved without throwing away links.
HESS also suffers from this exponential memory problem. It keeps all found links in memory and has to be killed after a certain amount of time as a result.
More intelligent fetching
The URLs that are found on a page are put in a simple queue. No effort has been put into making sure that this queue is emptied in a sensible manner.
In a possible future extension, the URL queue could be stored in a database and the fetchers could then ask for batches of URLs from a controller to this database. The controller could then make sure that the same domain isn't crawled too often and maybe even keep track of which domains are better to find email-addresses on. This would also be a better way to handle the memory problem than just keeping the queue in memory naively.
Weird addresses
RFC 2822 concisely describes what constitutes a valid email address, but not all valid email addresses according to this standard are real email-addresses. Images like github-logo@1200x1200.png are often found to be email addresses.
HESS could be extended with the (expensive) intention to also try and verify whether an email address is real. It is not provable that an email address is real. What does 'real' even mean here? We can find evidence however. Possible pieces of evidence include:
The domain exists and responds to pings
The SMTP server affirmatively answers a
RCPTquery
Of course these tactics have been used by spammers in the past, and will therefore probably end up having some less-exciting consequences like getting your IP-address banned from the SMTP servers.
Counteracting obfuscation
No effort has been made to counteract email address obfuscation. Because of the pipes architecture, it would be really easy to modularly add different ways to counteract specific obfuscations.
Some of these un-obfuscation techniques could be very expensive and are therefore probably not worth it. How would you un-obfuscate address<span style="display:none">muhaha</span>@example.com ? Lucky obfuscater!
Still, it could be interesting to try it out.
Results
The results depend a lot on the seed URL, of course. For generic seeds, I got up to one thousand possible email-addresses per minute. For really good seeds, that shot up to six thousand.
I invite you to replicate these results.
Conclusion
There are still a lot of unsolved problems in this area. I only spent a relatively short amount of time on this project and don't really intend to spend any more. It was fun, but I really don't have any use for a hard drive full of email-addresses.
Another Sunday afternoon well-wasted.