This post announces the new mergeful library. The mergeful library builds on ideas from the mergeless library which was published last year. In this part one, we describe how mergeful can help a server and its clients agree on a single value with safe merge conflicts.
Why
Using Smos on one machine is fine, but eventually you'll want to use it from multiple devices and/or make automatic backups of your workflow directory. Until recently, I have always put the smos files in a git repository and synchronised that using periodic commits. That worked fine for a while, but it is not what git is made for. What I would really like is a self-hosted central synchronisation server.
What
The synchronisation mechanism that is required for such a system is inherently complex but the complexity can be broken down nicely into three parts. The first part provides a mechanism for a server and its clients to cooperatively agree on a single thing of any type (that can be serialised). The second part extends this mechanism to "zero or one" of such a thing (we call this an 'Item'). The third part uses the second part to provide a mechanism to agree on a collection of values. This blog post discusses the first part. Part two and three will be described in a later blog post.
Each of the parts are documented nicely and can be used individually as well. Just be sure to follow the documentation in the respective modules on hackage.
How
Pieces of the puzzle
Just like in the mergeless library, the general workflow for this kind of sychronisation mechanism is as follows.
A central server and one or more clients want to cooperatively agree on an value of type a.
To start, the client needs to build a ClientValue a, but to do that it must first ask the server to send over the value that it has. This initial request only needs to happen once. After that, the following procedure suffices.
Clients store a ClientValue a value and the server stores a ServerValue a value. Clients regularly produce an ValueSyncRequest a value from their ClientStore using a makeValueSyncRequest :: ClientValue a -> ValueSyncRequest a function.
When the server receives an ValueSyncRequest a value, it uses its ServerValue a and an processServerValueSync :: ServerValue a -> ValueSyncRequest a -> (ValueSyncResponse a, ServerValue a) function to produce an ValueSyncResponse a and a new ServerValue a It then stores the new ServerValue a and sends the ValueSyncResponse a back to the client.
When the client receives the ValueSyncResponse a, it uses a mergeValueSyncResponse :: ClientValue a -> ValueSyncResponse a -> ClientValue a function to update its ClientValue a to reflect the new synchronised state.
The following diagram should help:
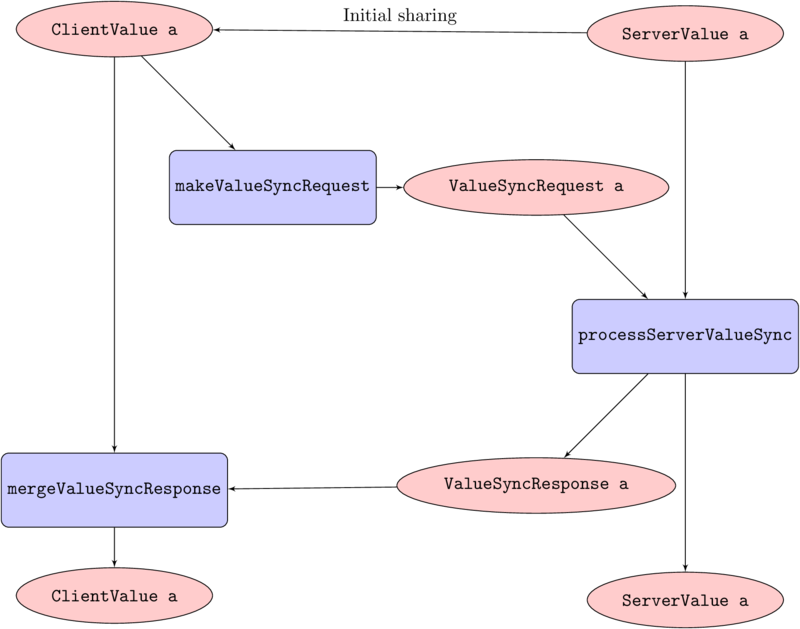
More about the particulars of these types and functions later.
Rejected ideas
I have been thinking about this concept for a long time now. When I wrote mergeless, it was because I realised that this problem becomes a lot easier if you can assume that values cannot be modified. Here are some ideas that I rejected over time, for various reasons.
Once you allow for modification of the value in question, the entire situation becomes a bit more tricky. Indeed, what do you do if both clients modify the value and then sync with the server? You could keep the version that was first synced to the server, but then you might lose work (certainly in the use-case of smos, that would be so). Ideally, the use-case would determine what should happen with conflicts and the library should not impose a conflict resolution strategy on the user.
If your particular use-case allows for a conflict-free replicated data type (CRDT), then it will probably be worth looking into the literature around that. Unfortunately neither JSON, YAML or even the subset of YAML in a .smos file allows for a CRDT approach.
A naive way to deal with conflicts could be to just sync as often as possible. This way two clients never try to modify the value before hearing about the others' modifications. As great as this sounds, it's not realistic. A client realistically does not have a permanent connection to the server. For example, a user may bring their device onto a plane and be disconnected for hours while working.
Another thing to think about is the following question: How should the server notice the difference between a conflicting modification and a non-conflicting modification if the client sends a different value than the one it has? Your first thought probably has something to do with modification timestamps. The server could say: if a different value arrives and it has a later timestamp, then it is a newer version. If it has an earlier timestamp, then it is a conflicting modification. So far so good, but there is a problem with that. Clients' timestamps are not something that can realistically be trusted. For a full list of falsehoods about time, be sure to have a look here. The problem that we have here is the following: Getting clients and the server to agree on time is not realistic. In particular, two machines probably have a shifted clocks and their clock will most likely also run at different speeds. (If this not immediately clear, consider airplanes and virtual machines.) This means that we cannot trust more than one machine's clock as the source of truth for time on all machines involved.
The next issue is that the value in question may be huge. Think multiple gigabytes. Ideally the client should not have to send over the entire value every time it wants to synchronise. It should only have to do that if any modifications have happened. This means that just sending over the entire client state every time is not feasible.
The last idea that turned out to be less than optimal was to not try to extend the concept of value-synchronisation to collection-synchronisation. You could argue that agreeing on a collection is the same as agreeing on a value which is a collection. The problem with this approach is that much more data will have to be transmitted, and that conflicts happen much more often and in a much less granular manner.
The mergeful solution
Mergeful allows for modifications of the values at the clients and lets clients decide how they deal with the conflicts. The way it deals with the problem of conflict versus new version is by using a single-node vector clock. What that means is that both the server and the clients only ever consider the timestamp of synchronisation as decided by the server. In fact, there is no need for an actual timestamp, but rather just some number that increases monotonically. We call this number the ServerTime but you can think of it as a version number.
newtype ServerTime = ServerTime { unServerTime :: Word64 }The server will automatically increase this number for every modification that is synced. This way no clocks need to be synchronised, and we do not need to make the assumption that clocks run equally quickly on all devices involved.
A value a with a ServerTime together is called a Timed a:
data Timed a = Timed
{ timedValue :: !a
, timedTime :: !ServerTime
}This type will be re-used in what follows.
The server will store a ServerValue a. A server value is just a Timed value that remembers when it was last changed.
data ServerValue a = ServerValue !(Timed a)The client needs to store the value that it has, and a flag that signifies whether the item has been changed since the latest sync.
data ChangedFlag
= Changed
| NotChanged
data ClientValue a
= ClientValue !(Timed a) !ChangedFlagWe could be tempted to re-use the ClientValue a as the ValueSyncRequest a but then we would be sending the value of synced values in every request. Instead, the ValueSyncRequest a type needs to be slightly different:
data ValueSyncRequest a
-- | There is an item locally that was synced at the given 'ServerTime'
= ValueSyncRequestKnown !ServerTime
-- | There is an item locally that was synced at the given 'ServerTime'
-- but it has been changed since then.
| ValueSyncRequestKnownButChanged !(Timed a)
deriving (Show, Eq, Generic)The difference lies in the ValueSyncRequestKnown constructor. It does not include the value at all, only the ServerTime of the value.
For the response value, there are four situations.
data ValueSyncResponse a
-- | The client and server are fully in sync.
--
-- Nothing needs to be done at the client side.
= ValueSyncResponseInSync
-- | The client changed the value and server has succesfully been made aware of that.
--
-- The client needs to update its server time
| ValueSyncResponseClientChanged !ServerTime
-- | This value has been changed on the server side.
--
-- The client should change it too.
| ValueSyncResponseServerChanged !(Timed a)
-- | A conflict occurred.
--
-- The server and the client both changed the value in a conflicting manner.
-- The server kept its part, the client can either take whatever the server gave them
-- or deal with the conflict somehow, and then try to re-sync.
| ValueSyncResponseConflict !(Timed a) -- ^ The item at the server side
deriving (Show, Eq, Generic)Actual synchronization
Once these types have been ironed out, we can start implementing the three crucial functions:
The makeValueSyncRequest function is fairly straight forward. All we need to do is not send over the value itself if the value has not been changed since it was synced.
makeValueSyncRequest :: ClientValue a -> ValueSyncRequest a
makeValueSyncRequest (ClientValue t cf) =
case cf of
NotChanged -> ValueSyncRequestKnown (timedTime t)
Changed -> ValueSyncRequestKnownButChanged tThe processServerValueSync function is the most interesting part of the whole approach. The comments explain what is going on.
-- | Serve an 'ValueSyncRequest' using the current 'ServerValue', producing an 'ValueSyncResponse' and a new 'ServerValue'.
processServerValueSync ::
ServerValue a -> ValueSyncRequest a -> (ValueSyncResponse a, ServerValue a)
processServerValueSync sv@(ServerValue t@(Timed _ st)) sr =
case sr of
ValueSyncRequestKnown ct ->
if ct >= st
-- The client time is equal to the server time.
-- The client indicates that the item was not modified at their side.
-- This means that the items are in sync.
-- (Unless the server somehow modified the item but not its server time,
-- which would beconsidered a bug.)
then (ValueSyncResponseInSync, sv)
-- The client time is less than the server time
-- That means that the server has synced with another client in the meantime.
-- Since the client indicates that the item was not modified at their side,
-- we can just send it back to the client to have them update their version.
-- No conflict here.
else (ValueSyncResponseServerChanged t, sv)
ValueSyncRequestKnownButChanged Timed {timedValue = ci, timedTime = ct} ->
if ct >= st
-- The client time is equal to the server time.
-- The client indicates that the item *was* modified at their side.
-- This means that the server needs to be updated.
then let st' = incrementServerTime st
in ( ValueSyncResponseClientChanged st'
, ServerValue (Timed {timedValue = ci, timedTime = st'}))
-- The client time is less than the server time
-- That means that the server has synced with another client in the meantime.
-- Since the client indicates that the item *was* modified at their side,
-- there is a conflict.
else (ValueSyncResponseConflict t, sv)The mergeValueSyncResponse function is not complex per-se, but requires the programmer to either make a choice as to what will happen in specific situations or to make it a bit more complex and general. It is left as an exercise to the reader.
Testing the implementation
Without the kind of test driven development using validity-based testing that I usually advocate for, I would have stood no chance of getting this code right at all. I found at least 4 deal-breaking bugs that had not crossed my mind at all.
This project is a great example of real-world validity-based property testing in practice. Notice the following aspects:
There are no unit tests, only property tests.
I did not write a single generator or shrinking function manually. Instead, they were all automatically generated using validity-based testing.
Many of the property tests come from either test suite combinators or property combinators.
There was no need for any fancy type-level magic to make things work reliably.
In particular, there is a specific property test that I would like to highlight:
it "is idempotent with one client" $
forAllValid $ \cstore1 ->
forAllValid $ \sstore1 -> do
let req1 = makeValueSyncRequest (cstore1 :: ClientValue Int)
(resp1, sstore2) = processServerValueSync sstore1 req1
cstore2 = mergeValueSyncResponseIgnoreProblems cstore1 resp1
req2 = makeValueSyncRequest cstore2
(resp2, sstore3) = processServerValueSync sstore2 req2
cstore3 = mergeValueSyncResponseIgnoreProblems cstore2 resp2
cstore2 `shouldBe` cstore3
sstore2 `shouldBe` sstore3This test succinctly specifies that if a client synchronises with a server twice, with whichever store they or the server may have, that will have the same result as just synchronising with the server once.
References
The mergeful library is available on Hackage. Mergeful originated in the work on Smos, Intray and Tickler. This post is part of an effort to encourage contributions to Smos. The simplest contribution could be to just try out smos and provide feedback on the experience. Smos is a purely functional semantic forest editor of a subset of YAML that is intended to replace Emacs' Org-mode for Getting Things Done.