I had an idea, made a proof of concept, and then built it out over a week. This is the story of how that happened.
During work it often comes up that I have to check whether a client accidentally leaked their secrets via their public code repositories. Often they do not have clients in the latest version of their code, but sometimes they do still have secrets somewhere in the history of their code. I figured I could write a little tool that could scan a git repository, both the current code and its history, to see if there were any secrets to be found.
I set up a little proof of concept in about five hours, to see if my ideas would work. I use Smos so I know exactly how much time I spent on this.
Getting set up
I use Haskell because (among many other reasons) it allows me to rapidly prototype an idea. I called it snotify because it would notify the user of secrets, and I find it funny that it sounds like spotify for snot. In this case I used a stack template to get up and running even quicker:
stack new snotify yesodweb/sqlite
I did not remove anything from the template that I did not need, but just coded what I needed.
Proof of concept
I needed some way to interact with a git repository. Hackage had (at least) two libraries to do that:
Either one would do the job, so I chose the one with more downloads: gitlib.
A git repository looks very complex, but the storage model can be summarised using this diagram.
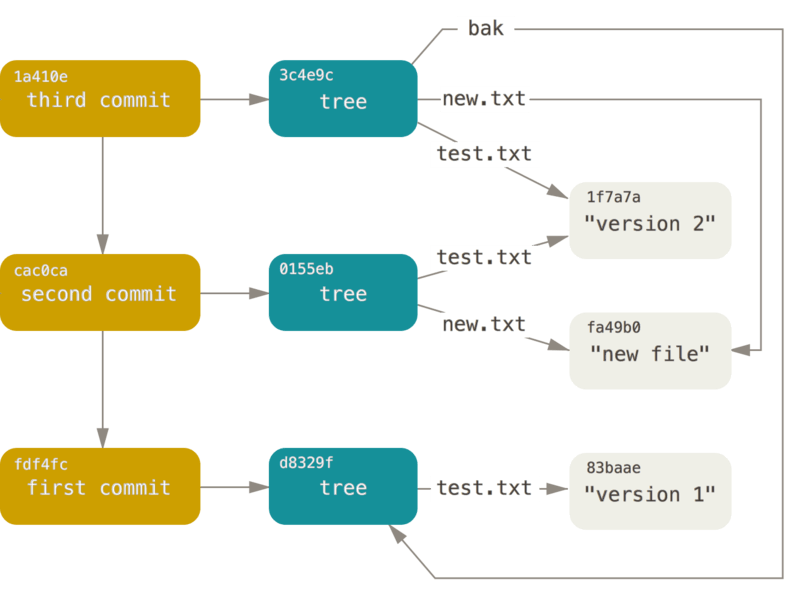
To find secrets, I employed the following preliminary algorithm:
Find all branches
For each branch, do the following
Follow each commit's parents back to the root
From the initial commit forward, go through each commit
For each commit, go through its tree recursively to find blobs and save that it has been analysed by its hash
For each blob, analyse it and cache that it has been analysed by its hash
Soon I was finding SSH keys. I knew that this was going to work.
Launching a first version
To get a first version running, I (mostly) made the most boring technology choices to get started:
Haskell because it is what I am the most comfortable with
Yesod, for the same reason
Sqlite for the database: Embedded, so no nonsense with getting it set up
Bootstrap for CSS, because I am terrible at making anything look good and their docs are great.
Nixops + Nixos + Nix for deployment, because I have already get a lot of it set up for other projects
In less than fourty work hours I had a working version up and running at https://snotify.cs-syd.eu. Making the algorithm for actually doing the analysis was by far the least time-consuming part. The most time consuming were authentication and getting automated email notifications set up.
A quick look at competitors
I found at least one competitor for a service like this, and I noticed that they did not find most of the keys that snotify finds. I read on their website that they use ML to find the keys, so I am not really surprised. I also found that many services detect their own API keys being leaked. I.e. GitHub will tell you if there is a GitHub API key in a GitHub repository and AWS will tell you if you leave an AWS api key in a GitHub repository as well.
Next steps: Marketing!
The next steps will consist mostly of trying to get people to actually use snotify. If everything goes well enough, I will come up with a monetisation strategy. For now, all of snotify works for free.
To be quite honest: I have no idea how to do marketing, but I have some ideas:
Blogposts like this one (thanks for reading it, by the way)
Poking my friends until they try it out
If you would like to share some more ideas for marketing, please send an email. I also welcome any and all feedback.